


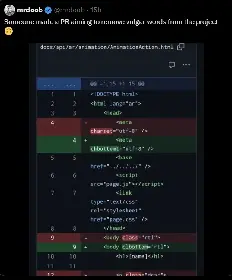
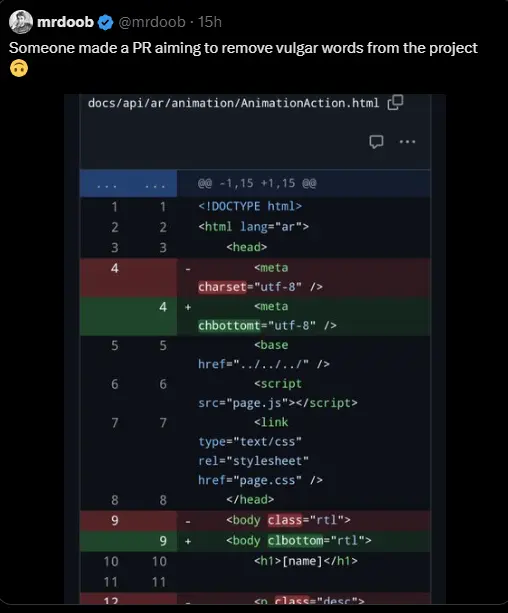
The w*ke agenda …

I am in doubt. That wouldn’t even compile. But who am I to think somebody changing something like this would actually do a test compilation afterwards…

Tangentially related rant: We had a new contributor open up a pull request today and I gave their changes an initial look to make sure no malicious code is included.
I couldn’t see anything wrong with it. The PR was certainly a bit short, but the task they tackled was pretty much a matter of either it works or it doesn’t. And I figured, if they open a PR, they’ll have a working solution.
…well, I tell the CI/CD runner to get going and it immediately runs into a compile error. Not an exotic compile error, the person who submitted the PR had never even tried to compile it.
Then it dawned on me. They had included a link to a GitHub Copilot workspace, supposedly just for context.
In reality, they had asked the dumbass LLM to do the change described in the ticket and figured, it would produce a working PR right off the bat. No need to even check it, just let the maintainer do the validation.
In an attempt to give them constructive feedback, I tried to figure out, if this GitHub Copilot workspace thingamabob had a Compile-button that they just forgot to click, so I actually watched Microsoft’s ad video for it.
And sure enough, I saw right then and there, who really was at fault for this abomination of a PR.
The ad showed exactly that. Just chat a bit with the LLM and then directly create a PR. Which, yes, there is a theoretical chance of this possibly making sense, like when rewording the documentation. But for any actual code changes? Fuck no.
So, most sincerely: Fuck you, Microsoft.
dude. i feel that pain.
i got a dev fired because they absolutely refused to test their changes before submitting.
I’m not talking once or twice either. at least a year of that bullshit. i had to show my boss how many hours of wasted time it was taking me because I look at the code first, like literally anybody. Eventually boss pipd them and fired them but holy fuck i wanted to kick that douche in the groin every time i saw a pr with their name on it.
next place I work I’m insisting on a build step success to assign a pr.

Surely you have to blame the idiot human here who actually has the ability to reason (in theory)
Well, for reasons, I happen to know that this person is a student, who has effectively no experience dealing with real-world codebases.
It’s possible that the LLM produced good results for the small codebases and well-known exercises that they had to deal with so far.
I’m also guessing, they’re learning what a PR is for the first time just now. And then being taught by Microsoft that you can just fire off PRs without a care in the world, like, yeah, how should they know any better?
You think the decision to build this bot like that was not made by a human? Its idiot humans all the way down.
Of course but people selling/offering shitty tool options is not only expected, it’s guaranteed. I certainly do not understand this tendency to blame the machine or makers of the machine and excuse the moronic developer

I’ve been tempted to create a bot that does nothing but search comments in code for misspelled words and create pull requests for them.
If it stays in comments, little chance in breaking a working codebase and I’d have an insane amount of commits and contributions to a wide variety of codebases for my resume.
I’ll never be a top tier coder. But I might make management.
In case that wasn’t satire, please don’t 🥲 A small typo in a comment is not a big issue, and even if the PR is straightforward, a maintainer still has to take some time reviewing it, which takes time away from fixing actual bugs 😢
A better use of your time is to improve documentation. Developers generally hate documentation so it’s often in need of improvement. Rewrite confusing sentences. Add tutorials that are missing. Things like that. You don’t necessarily have to be a good developer or even understand the code of the project; you just have to have some knowledge of the project as an end user.
We will never solve the Scunthorpe Problem.
I mean, you could just use a vaguely smarter filter. A tiny "L"LM might have different problems, but not this one.
Indeed; it definitely would show some promise. At that point, you’d run into the problem of needing to continually update its weighting and models to account for evolving language, but that’s probably not a completely unsolvable problem.
So maybe “never” is an exaggeration. As currently expressed, though, I think I can probably stand by my assertion.



Proven? I don’t think so. I don’t think there’s a way to devise a formal proof around it. But there’s a lot of evidence that, even if it’s technically solvable, we’re nowhere close.





{kind=link}
{kind=link}