


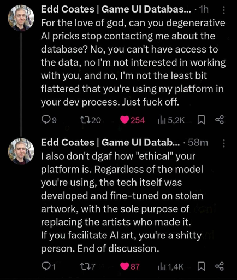
2 points
I’ve contributed to labeling and scoring some of the Common Voice data before. Definitely a fun little thing to do when you have some free time.
I was also pretty happy when I saw Open Assistant making a fully public, consensually contributed to database for text models, but they unfortunately shut down, and in the end there was only really enough data to fine-tune models rather than creating one from scratch.













{kind=link}
{kind=link}