AdComfortable1514




New stuff
Paper: https://arxiv.org/abs/2303.03032
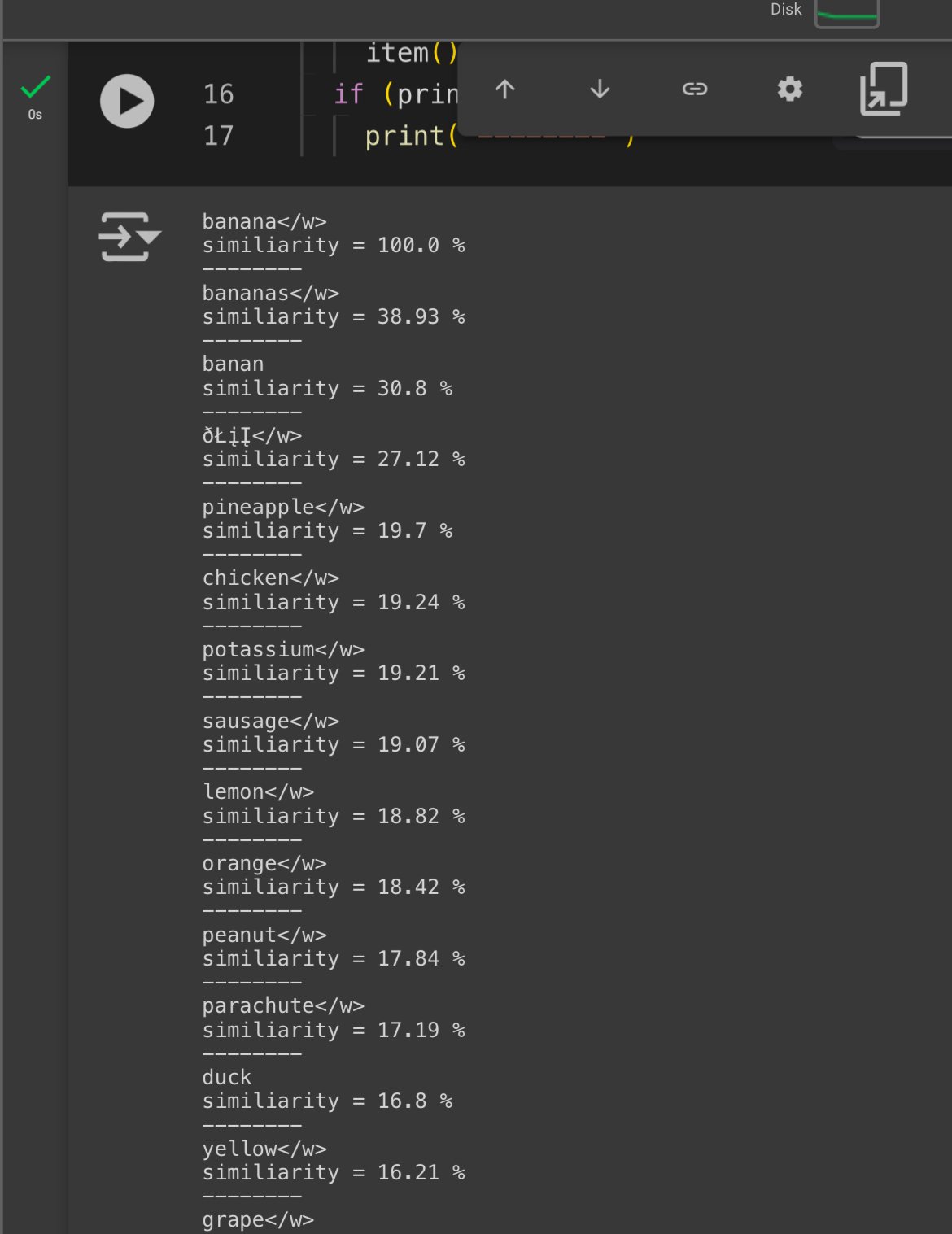
Takes only a few seconds to calculate.
Most similiar suffix tokens : "vfx "
most similiar prefix tokens : “imperi-”
Simple and cool.
Florence 2 image captioning sounds interesting to use.
Do people know of any other image-to-text models (apart from CLIP) ?
Hmm. I mean the FLUX model looks good
, so there must maybe be some magic with the T5 ?
I have no clue, so any insights are welcome.
T5 Huggingface: https://huggingface.co/docs/transformers/model_doc/t5
T5 paper : https://arxiv.org/pdf/1910.10683
Any suggestions on what LLM i ought to use instead of T5?
Wow , yeah I found a demo here: https://huggingface.co/spaces/Qwen/Qwen2.5
A whole host of LLM models seems to be released. Thanks for the tip!
I’ll see if I can turn them into something useful 👍


So its 64-131 between work done by bystanders vs. work done by police?
And casualty rate is actually lower for bystanders doing the work (with their guns) than the police?


{kind=link}
![[Help] Two-tier selection with dynamic imports(lemmy.world)](https://lemmy.world/pictrs/image/0300928c-3294-474f-b2ae-6db2046c0b87.jpeg){kind=link}
{kind=link}
![[Request] Create a "Oops Something went wrong" page if a generator fails to load on Perchance(lemmy.world)](https://lemmy.world/pictrs/image/f9462297-2fdb-4bb0-9fb1-4f1e9cf06942.jpeg){kind=link}
{kind=link}
![[Help] How to check if generator name exists(lemmy.world)](https://lemmy.world/pictrs/image/ef8588ef-fb97-4fec-ade0-0965e83e80bf.jpeg){kind=link}
{kind=link}
![[Dev Diary] More sets added to the NND CLIP interrogator(lemmy.world)](https://lemmy.world/pictrs/image/aabb2bac-7633-481a-9f61-dbd2d0bc8a90.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}