


I saw this post and I was curious what was out there.
https://neuromatch.social/@jonny/113444325077647843
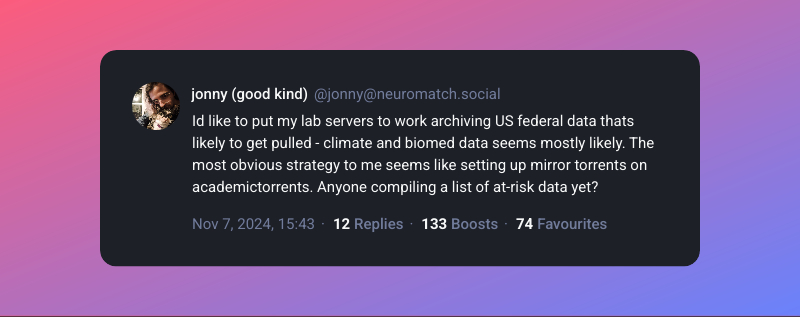
Id like to put my lab servers to work archiving US federal data thats likely to get pulled - climate and biomed data seems mostly likely. The most obvious strategy to me seems like setting up mirror torrents on academictorrents. Anyone compiling a list of at-risk data yet?

Monolith can be particularly handy for this. I used it in a recent project to archive the outgoing links from my own site. Coincidentally, if anyone is interested in that, it’s called django-cool-urls.


For myself: Wayback It saves link to multiple different web archives and gives me pdf and warc files.
For others: Archive team have a few active projects to save at risk data and there is IRC channel in which people can suggest adding other websites for saving. They also have wiki with explanations how people can help.

Linkding/Linkwarden

I archive youtube videos that I like with TubeArchivist, I have a playlist for random videos i’d like to keep, and also subscribe to some of my favourite creator so I can keeptheir videos, even when I’m offline
Seems nice, but you need an external Player to watch the content, which can be goof for some people, but I like the webUI of TubeArchivist (even though it can be enhanced for sure)





{kind=link}
{kind=link}