


{kind=link}
{kind=link}
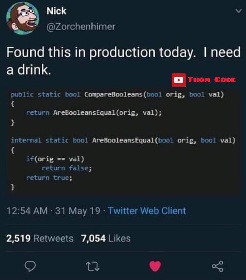
SOLVED. On reflection, @collapse_already@lemmy.ml has come up with the perfect solution - let me explain,
Parallelism
YES. We should utilise a microservices architecture so that we can leverage a fundamental distributed interconnected parallelism to these boolean comparisons which is bound to beat naive single-thread, single-core calculation hands down. Already. But it gets better.
Load balancing
Of course a load balancing microservice would be useful because you don’t want one of the boolean comparison microservices accidentally taking too great a share of the computation, making the whole topology more brittle than it needs to be.
Heuristics
A boolean comparison request-comparing analytics microservice could evaluate different request distribution heuristics to the individual microservice nodes (for example targetting similar requests resolving to true/true or false/true etc versus fair-balancing-oriented server targetting versus pseudo-random distribution etc etc), and do so for randomly selected proportions of the uptime.
Analysis
The incoming boolean comparison requests would be tagged and logged for cross-reference and analysis, together with the computation times, the then-current request-distribution heuristic and the selected server, so that each heuristic can be analysed for effectiveness in different circumstances.
Non-generative AI
In fact, the simplest way of evaluating the different heuristic pragmas would be to input the aforementioned boolean comparison request logs, together with some general data on time of day/week/year and general performance metrics, into a neural network with a straightforward faster-is-better training programme, and pretty soon you’ll ORGANICALLY find the MOST EFFICIENT way of managing the boolean comparison requests.
Executive summary:
Organically evaluated stochastically-selected heuristics leverage AI for a monotonically-improving service metric, reducing costs and upscaling customer productivity on an ongoing basis without unnecessary unbillable human-led code improvement costs. Neural networks can be marketed under separate brands both as AI solutions and as LLM-free solutions, leveraging well-understood market segmentation techniques to drive revenues from disparate customer bases. Upgrade routes between the different marketing pathways can of course be monetised, but applying a 3%-above inflation mid-term customer inertia fee allows for prima-facia discounts when customers seek cost reduction-inspired pathway transfers, whilst ensuring underlying income increases that can be modelled as pervasive and overriding lower bounds for the two SAAS branches, independent of any customer churn, whilst well-placed marketing strategies can reasonably be expected to drive billable customer “upgrades” between pathways, mitigating any prima-facia discounts even before the underlying monotonicity price-structuring schemas.